conga is a distributed congestion-aware load balancing for datacenters published on sigcomm 2014.
introduction
ECMP(equal cost multipath load balancing) load poorly because:
- ECMP randomly hashes flows to paths, not caring whether it is a large flow.
- ECMP uses local decision, with no knowledge of congestion of each path.
- hard to deal with link failure.
To address ECMP’s short comings, prior work can be classified as:
- centralized scheduling, e.g. Hedera. Too slow for the traffic volatility.
- local switch mechanisms, e.g., Flare. Local congestion aware mechanisms are suboptimal, thus performing worse.
- host-based transport protocols, e.g. MPTCP. Hard to deploy since it needs end-host stack changed, considering problems like control/bypass/new-protocol. Also add complexity.
Target: in the network instead of transport layer, globally optimal, rapid reaction(ms), standard encapsulation formats fitting.
design consideration
distributed vs. centralized
The datacenter traffic is bursty and unpredictable. Datacenters use regular topologies. In this condition, distributed approach can react rapidly and the decisions are close to optimal.
If a network has stable and predictable traffic and arbitrary topology, a centralized approach is a good choice, i.e. google’s inter-datacenter traffic engineering algorithm.
in-network vs. end-host
The datacenter fabric should behave like a large switch.
MPTCP works, but increases congestion at the edge of the network and the burstiness of traffic as more sub-flows contend at the fabric’s access links. Sometimes MPTCP cannot be used when the kernel bypassed.
global vs. local
non-local knowledge about downstream congestion helps. Especially at the situation when some links fail.
leaf-to-leaf feedback
Conga works in an overlay network. In the additional headers, the congestion metrics can be carried.
flowlets vs. flow
Flowlets are bursts of packets from a flow that are separated by large enough gaps. Datacenter traffic is extremely bursty at short timescale, flowlets switching is a fine-grained load balancing. The cost to distinguish flowlet concurrency is feasible.
design
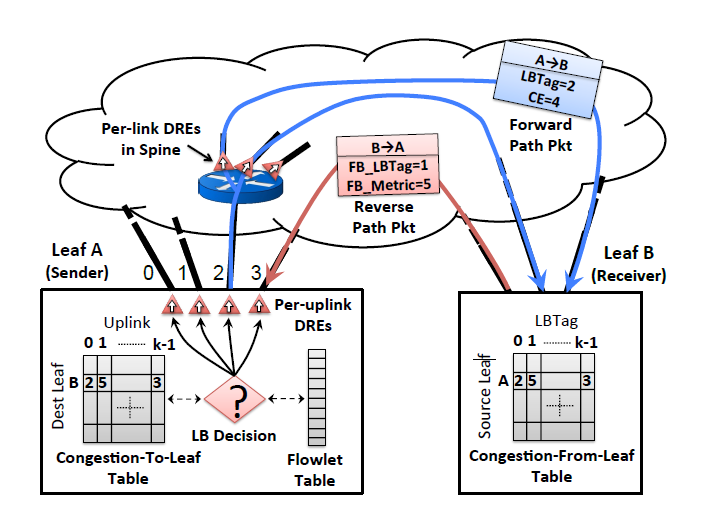
Each leaf updates a Congestion-to-leaf table, a congestion-from-leaf table, and a flowlet table. At the VXLAN overlay header, LBTag denotes the uplink port, CE updates on the path to convey the extent of congestion. Specifically, each switch maintains a register X, incremented for each packet transmitted by the packet size, decremented periodically ($T_{dre}$) with a multiplicative factor $\alpha$ between 0 and 1. $X \leftarrow X \times (1-\alpha)$. In this way $X \approx R \cdot \tau, \tau=T_{dre}/\alpha$, where R is the sending rate. The extent of congestion is demonstrated as $X/C\tau$ to 3 bits, C is the bandwidth. (Discounting Rate Estimator, DRE) FB_LBTag indicates an uplink port and FB_Metric provides its congestion metric.
Congestion-from-leaf table caches the metrics, waiting for piggybacking packet or explicit feedback. Each time it selects one metric to send, such as round-robin.
Congestion-to-leaf table updates the feedback. Aging mechanism is added when a metric not updated for a long time gradually decays to 0.
Each entry of a flowlet table consists of a port number, a valid bit and an age bit. The table is for flowlet detection and temporally saving the uplink path.
For a new flowlet, we pick the uplink port that minimizes max(local DRE, remote metric(c-t-l table)). When multiple path are equally good, one is chosen at random with preference given to the port cached in the invalid entry in the flowlet table.