instruction
Data-center network stacks are moving into hardware to achieve 100 Gbps data rates and beyond at low latency and low CPU utilization. However, hardwiring the network stack in the NIC would stifle innovation in transport protocols. In this paper, we enable programmable transport protocols in high-speed NICs by designing Tonic, a flexible hardware architecture for transport logic. At 100 Gbps, transport protocols must generate a data segment every few nanoseconds using only a few kilobits of per-flow state on the NIC. By identifying common patterns across transport logic of different transport protocols, we design an efficient hardware “template” for transport logic that satisfies these constraints while being programmable with a simple API. Experiments with our FPGA-based prototype show that Tonic can support the transport logic of a wide range of protocols and meet timing for 100 Gbps of back-to-back 128-byte packets. That is, every 10 ns, our prototype generates the address of a data segment for one of more than a thousand active flows for a downstream DMA pipeline to fetch and transmit a packet.
background
- data center up to 100Gbps ethernet: processing time for each segment only 10ns
- offload the whole network stack to hardware
- currently only a few version of transport protocol implemented on NICs, modified only by vendors.
motivation
- programmable transport logic is the key to enabling flexible hardware transport protocols.
- we can exploit common patterns in transport logic to create reusable high-speed hardware modules.
architecture
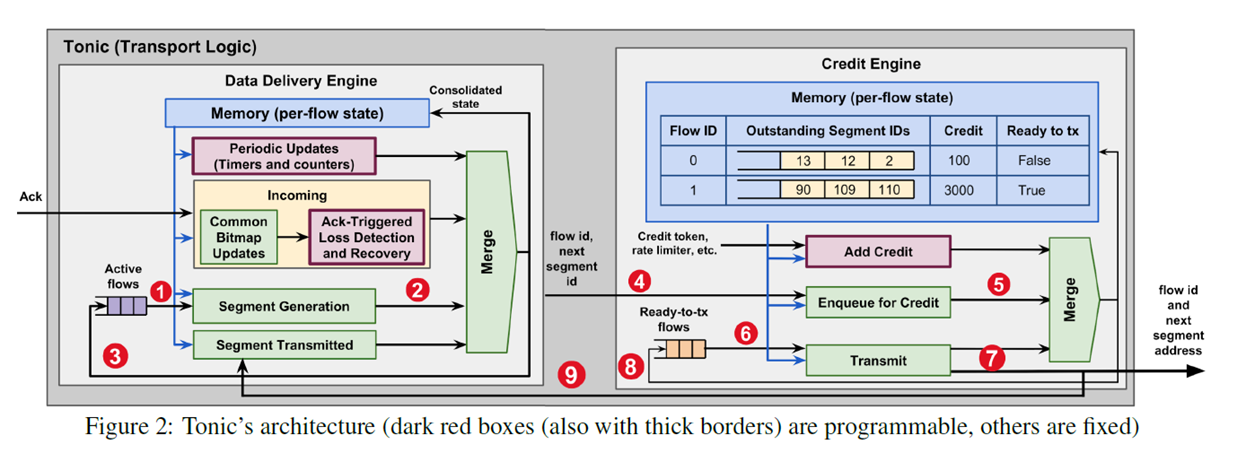
- connection management controlled by software
- data accessed through DMA, only segment address used in tonic
- what-to-send and when-to-send partitioned to data delivery engine and credit engine
- if a flow need to send segment, it would be pushed into active flow in data delivery engine, processed by segment generation module. Only if it has more segments to send, it was inserted back into the set. The credit engine receives the flow id and next segment id, inserts it into the ring buffer for the flow. Once this flow has enough credit and the segment is ready to send, it is inserted into ready-to-tx flows. Each cycle a flow is selected and a segment is transmitted, credit decreased, data delivery engine signaled. Check the number in the figure.
- data traced in the level of segment. the segment is in a fixed size configured at each flow started.
- the amount of segment for each flow in flight is limited, such as 256/128.
- use bitmap to trace all the segment
- in the figure, green boxes are fixed-function, while red boxes are programmable modules, for congestion control.
evaluation
good resource utilization and scalability
function works like hard-coded protocol on NICs.